A few weeks ago, I did a blog post introducing the “EDAC” functions in Legato with a very brief example of how to create an NPORT filing and fill in a few fields. Well, I thought we would take that a few steps further, and show how you can use that to create an import function for a complex table like the Part C section of NPORT. This table is fairly involved because it has three possible layers of sublists (lists contained in other lists), and we’ll need to keep track of this. Therefore, this blog is going to discuss a lot of “level 1”, “level 2”, and “level 3” tables, all of which occur within a single data table. To help visualize what exactly is meant by these different levels, take a look at this screenshot from GoFiler:
Friday, March 01. 2019
LDC #125: Advanced Application of EDAC: Importing NPORT Part C
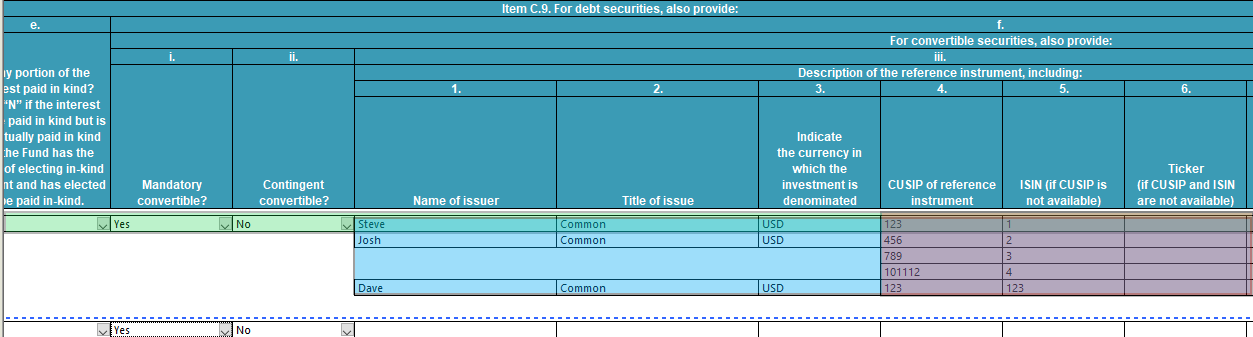
The green highlighted area represents a level 1 row. The blue highlighted area represents a list within that list (level 2), starting with the Name of Issuer field, that contains for three rows. The purple highlighed area represents a level 3 list, which is a list within the list within the list. This data starts with the CUSIP of the reference instrument, and you can see that Steve (level 2, row 1) and Dave (level 2, row 3) only have one CUSIP list item, while Josh (level 2, row 2) has three. This list within lists feature of NPORT is what makes the importer more complicated than a normal import function. We need to account for these nested lists as we go through the data set.
Our importer is going to work off a very simple template. The template file (you can download a copy of that here) is very basic. Across the top row we have the actual names GoFiler is expecting for the elements. I refer to these as “key” values often in this blog entry, because they’re often used as keys to set values. I’ve modified them slightly though, so instead of having an actual numerical identifier in the brackets, they have the ‘%03d’ string, which can be easily stripped out and replaced by a numeric value as we count lists and nested lists. The script is going to have to go through the data of our file, line by line, and import it. Whenever we encounter a sub list (which we can identify by having two or more ‘%03d’ strings in the first line of that column), we need to import it, store its depth so we don’t try to import it again, and store its width so our main parsing function can skip over already imported data. It’s deceptively complicated, so lets dive into how our script is going to work.
#define FILENAME "C:\\Users\\steven.horowitz\\Desktop\\Part C.csv" int process_table (); int process_l2_nested_list (string key,int col_start,int l2x_start); int process_l3_nested_list (string key,int col_start,int l3x_start); int get_level (string element);
In order to keep this script as simple as possible, there is no UI element. I’ve hard coded the path to the CSV file as the define FILENAME. Anyone trying to duplicate this should either modify the path to something on his or her own local system or add in a UI function to gather the path and file from the user.
Below our define, we have our four primary functions that make up this script. The process_table function is the basic function called to import our table, and it will be called by the main function. The other two list functions, process_l2_nested_list and process_l3_nested_list, are called when a level 2 or level 3 list are encountered. They are very similar in function, and it’s possible to combine them into a single “process_nested_list” function, but I found doing that increased the complexity of the function significantly and made it a lot more difficult to debug. So instead we have a bit of repetitive code, which isn’t usually a great idea, but in this case it gives us code that is much easier to read and debug, which is the trade-off. Our last function, get_level, is very simple: it takes a key value and breaks down how many ‘%03d’ strings appear in it, so we know what level our key represents.
First, here’s the main function of this script:
/****************************************/
int main(){ /* main function */
/****************************************/
int rc; /* return code */
int ix; /* counter variable */
int cx; /* column counter */
string vals[]; /* values */
string directive; /* directive to enter */
string data; /* value to enter */
/* */
ArrayClear(csv); /* clear CSV */
csv = CSVReadTable(FILENAME); /* read the file */
rc = GetLastError(); /* get error code */
if (IsError(rc)){ /* if we have an error */
MessageBox('x',"Cannot read file %s",FILENAME); /* display error */
return ERROR_EXIT; /* return error */
} /* */
The main function starts off by clearing the global csv variable and then reading the new table with the CSVReadTable function. If that function returns an error, we need to display that error message and immediately abort because we cannot do anything else unless we can read the table.
csv_rows = ArrayGetAxisDepth(csv); /* get depth of CSV */
width = ArrayGetAxisDepth(csv,1); /* get width of CSV */
AddMessage("Rows in data set: %d",csv_rows); /* display message */
rc = RunMenuFunction("FILE_NEW_SUBMISSION", "Form:NPORT-P"); /* create the NPORT filing */
if (IsError(rc)){ /* if it's an error */
AddMessage("Error: 1 %0xd",rc); /* return error */
return ERROR_EXIT; /* return */
} /* */
edac = EDACOpenView(); /* */
rc = process_table(); /* process list table */
return ERROR_NONE; /* return without error */
} /* */
After reading the CSV file, we can use the ArrayGetAxisDepth function to get the number of rows in the table (depth) and the number of columns (width). We’ll need this information later. Finally we can use the RunMenuFunction function to create our actual project file. This example is creating an NPORT-P form, though if we were doing this for production, again, we’d have a UI element there to ask the user what the form type is. After running that function and testing to make sure it was successful, we can get the EDAC handle to our new project file and enter the process_table function to start reading in data.
/****************************************/
int process_table(){ /* process table directive */
/****************************************/
... omitted variable declarations ...
/* */
AddMessage("Beginning processing table"); /* add message */
row = 0; /* start on row 0 */
ArrayClear(keys); /* reset keys list */
level_1_data_start = 1; /* store column of data start */
l1x = 0; /* level 1 index */
l2x = 0; /* level 2 index */
l3x = 0; /* level 3 index */
next_row = -1; /* init next row */
Before going any further, we need to initialize all our variables at the start of process_table. This isn’t explicitly required when running non-hooked functions, since their variables are all cleared each time a script is run anyway. However, it’s good to get into the habit of doing it because when this is run as a hooked function, global variables are not cleared until the application exits. This means you might have uninitialized values causing odd behaviors unless you plan for them like this.
for(ix=1; ix<width; ix++){ /* for each column in CSV */
val = TrimString(csv[row][ix]); /* get value in cell */
if(val!=""){ /* if a value is there */
positions[cx] = ix; /* store position */
keys[cx] = val; /* store value */
levels[cx] = get_level(val); /* get the level of the key */
cx++; /* increment counter */
} /* */
} /* */
After initializing our variables, we can go ahead and iterate over each column in the first row of the CSV file. We’re looking for non-empty cells here, so we can store the position of that column, the name of that column, and what level that column is. We need to store the position in a separate array just in case there is a blank column in our headings (thus meaning we cannot rely on the column index being exactly equal to the number of columns in the table). We can also increment a column counter, cx, to get the number of columns containing data.
AddMessage("Columns - %d",cx); /* get number of columns */
while(true){ /* while next directive is not end list */
l1x++; /* increment row counter */
if(l1x>=csv_rows){ /* if we're beyond the edge of the table*/
return ERROR_NONE; /* return no error */
} /* */
next_row++; /* increment ID of next row */
for(ix=0; ix<cx; ix++){ /* for each column */
level = levels[ix]; /* get the level */
if(level > 1){ /* if we have a multi-level table */
if(level == 2){ /* if it's a level 2 list */
next_col = process_l2_nested_list(keys[ix], ix, /* */
row+l1x); /* pass level start point info */
} /* */
if(next_col <= ix){ /* should never happen */
return ERROR_EXIT; /* return with error */
} /* */
ix = next_col; /* set to next column to process */
} /* */
Now we can enter our main processing loop for this list. Using a loop like this (with the loop’s conditional simply being true) can be dangerous, so make sure that if you ever choose a coding construct like this that there is always a way for the loop to break. Otherwise you can get stuck in an infinite loop. The very first thing we do is increment our l1x counter. This variable corresponds to the row in the data table we’re currently processing, which is not always the same as the data row. Next, our loop checks if our row counter is beyond the number of rows in the table. If so, we can return. This is our failsafe here. Since the row counter is always incremented, this condition should always eventually become true, so our loop will eventually return. Next we can increment our next_row variable. This is important. We cannot just use the l1x counter as our next row, because if we encounter a level 2 list that is three elements deep, our next row will only increment by 1, but our l1x counter will increment by three.
After that, we can iterate over each column in our row with a for loop and get the level for the current column. If the level is greater than one and it’s level 2 (it should never be level 3, because the table is structured in such a way that all level 3 tables should be within level 2 tables), we can run our process_l2_nested_list function to handle it. If our next column is greater than the number of columns, we can return an error. This should never happen, and the only time it could happen is if our level 2 processing function encountered an error and returned a bad value. Otherwise, we can just set our column counter to the next column value. This next column value, next_col, is returned by the process_l2_nested_list function. When handling a level 2 table, this function is supposed to return the next column that is not part of a level 2 or level 3 table, so we can resume processing the table at the next level 1 column we encounter.
else{ /* if level 1 */
key = keys[ix]; /* get key */
position = positions[ix]; /* get position of value */
val = csv[row+l1x][position]; /* get value */
if(val!=""){ /* if value is defined */
AddMessage(" Found L1 field %s, value '%s'", key, val); /* log message */
} /* */
if(key!=""){ /* if this column has a key */
val = TrimPadding(val); /* trim padding */
if(val!=""){ /* if the field has a value */
if (MakeLowerCase(val) == "yes" || /* if data is Yes */
MakeLowerCase(val) == "no"){ /* or if data is No */
val = FormatString("%c",val[0]); /* truncate to first character */
} /* */
key = FormatString(key,next_row); /* format string for key */
rc = EDACSetItem(edac,key, val); /* run EDAC update */
if(IsError(rc)){ /* if we have an EDAC error */
LogSetMessageType(LOG_ERROR); /* set log type to error */
AddMessage(" Cannot add L1 %s value '%s', code %0x", /* log error */
key,val,rc); /* log error */
LogSetMessageType(LOG_NONE); /* set back to normal */
} /* */
else{ /* if not an EDAC error */
AddMessage(" Added %s value '%s'.", /* log success */
key,rowdata[ix][1]); /* log error */
} /* */
} /* */
} /* */
} /* */
} /* */
If our column is not higher than level 1 though, we can process it here. We can get the key and position for this column from our keys and positions arrays, and get the value out of the csv variable. If the value isn’t empty, we can report that we found a value through the AddMessage function. If the key isn’t empty (and it never should be), we can trim the value to get rid of white space, and as long as the value isn’t blank now, we can test if it’s either “yes” or “no”. We need to get just the first character since EDAC doesn’t understand “Yes” or “No”; it simply processes “y” or “n”. Once we have our value set correctly, we can use the FormatString function to insert our next row ID into our key template from the table and use the EDACSetItem function to set the created key to the new value. After that, we can check the return code, and if it’s an error, we can log it. Otherwise, we log that a value was added successfully.
if(l2_max_depth > 1){ /* if l2 contains multiple rows */
AddMessage("L2 Depth is: %d",l2_max_depth); /* display message */
l1x += (l2_max_depth - 1); /* add the depth of L2 */
} /* */
l2_max_depth = 0; /* reset max depth of nested list */
} /* */
return ERROR_NONE; /* return no error */
} /* */
The last thing we need to do here is check to see if the l2_max_depth value has changed. If we entered a level 2 table while processing this row, that table might have been more than a single row deep. If so, we need to take the max depth of the level 2 table and add it to our l1x counter. This way, we don’t try to process a level 2 row as a level 1 row on our next pass through. Then we can reset our l2_max_depth variable and go back for the next data row.
/****************************************/
int process_l2_nested_list(string key,int col_start,int l2x_start){ /* process nested list */
/****************************************/
... variable declarations omitted ...
/* */
level_2_data_start = col_start; /* get column this starts on */
l2x = 0; /* reset level 2 depth, new l2 list */
size = GetStringLength(key); /* get size of prefix string */
for(ix=0;ix<size;ix++){ /* scan string */
if(key[ix]==':'){ /* if this is a colon char */
end_prefix = ix; /* store last colon pos */
} /* */
} /* */
prefix = GetStringSegment(key,0,end_prefix); /* get prefix */
keystart = FindInList(keys,key); /* find first occurance of prefix */
size = ArrayGetAxisDepth(keys); /* get length of keys */
for(ix=keystart;ix<size;ix++){ /* for each item in the array */
kix = FindInString(keys[ix],prefix); /* find key index */
if(kix>=0){ /* if the next col has same prefix */
current_width++; /* increment width */
} /* */
else{ /* */
ix=size; /* end loop */
} /* */
} /* */
Processing a level 2 list is similar to processing a level 1 list, but before we do anything we need to establish the width of the level 2 list. To do this, we can iterate over each character in the key on which a level 2 list is starting and keep going until we find a colon character. If we find one, we store its position.
Eventually this will leave us with the position of the last colon character in the key. We can then use the GetStringSegment function to get the portion of the string from the beginning to the last colon. This can be considered our “prefix” for this level 2 table. Once we have our prefix, we can use the FindInList function to find the first occurrence of this prefix in our table, and then iterate over every column in our table. If the next column we’re looking at has the same prefix, we can increment our current width counter. If not, we can set ix to the size of our list, which escapes the loop.
AddMessage("Process L2 List, Width: %d",current_width); /* display message */
next_l2_row = -1; /* the next row in l2 to use */
while(true){ /* loop until invalid data */
for(ix = 0; ix < current_width; ix++){ /* for each cell in width */
key = keys[keystart+ix]; /* get the key */
if(get_level(key)==3){ /* if this is a level 3 key */
ix+=process_l3_nested_list(key,col_start+ix, /* process the level 3 list */
l2x_start+l2x); /* */
} /* */
else{ /* if it's level 2 */
val = csv[l2x_start + l2x][col_start+ix+1]; /* value to set */
if(ix==0){ /* if this is the first cell */
if(val == ""){ /* if cell is empty */
break; /* go for next row */
} /* */
else{ /* if the cell is not empty */
next_l2_row++; /* increment next L2 Row Counter */
} /* */
} /* */
Now that we have our width for the level 2 table, we can iterate over rows until we hit the end of the table or the end of the level 2 list the same way we do for level 1 lists: with an infinite loop. The first thing we do after we enter the loop is we iterate over every column in the width of our level 2 table. We can get the key value for the column, and if the key is a level 3 key, we need to enter our level 3 processing function. Otherwise, we can continue processing it as level 2 by first getting the value of data for our next cell out of the table, and then checking to see if it’s empty. If so, we can just break the loop here because this isn’t a valid data row. Our model assumes that every level 2 table will have data in the first cell, since the first cell is always an ID or Name field (which is required by the SEC anyway). If it isn’t blank, we can increment our next_l2_row counter so we have a valid ID for our level 2 row we’re processing.
new_key = FormatString(keys[keystart+ix],next_row, /* key to use */
next_l2_row); /* key to use */
AddMessage(" Found Value: %s",val); /* display value */
val = TrimPadding(val); /* trim padding */
if(val!=""){ /* if we have a value to add */
if (MakeLowerCase(val) == "yes" || /* if data is Yes */
MakeLowerCase(val) == "no"){ /* or if data is No */
val = FormatString("%c",val[0]); /* truncate to first character */
} /* */
rc = EDACSetItem(edac,new_key, val); /* run EDAC update */
if(IsError(rc)){ /* if we have an EDAC error */
errors++; /* add error to log */
LogSetMessageType(LOG_ERROR); /* set log type to error */
AddMessage(" Cannot add %s value '%s', code %0x", /* log error */
new_key,val,rc); /* log error */
LogSetMessageType(LOG_NONE); /* set back to normal */
} /* */
else{ /* if not an EDAC error */
AddMessage(" Added %s value '%s'.", /* log success */
new_key,val); /* log error */
Now that we’ve established the row has valid data and we’ve established the row ID, so next we need to set the value of our key with the FormatString function, putting in the next_row and next_l2_row variables as our parameters, to give it the correct ID values. That way EDAC will apply it correctly. Then, like with the level 1 row, we can trim the value, test if it’s “yes” or “no” (‘y’ or ‘n’), use the EDACSetItem function to set it into our table, and test the return code.
} /* */
} /* */
}
} /* */
l2x++; /* increment row counter */
if(csv[l2x_start + l2x][level_1_data_start]!=""){ /* if the next data row is starting */
if(l2x>l2_max_depth){ /* if this is the deepest L2 yet */
AddMessage("Max L2 Depth: %d",l2x); /* Add Message */
l2_max_depth = l2x; /* store end position of l2 list */
} /* */
return col_start+current_width-1; /* return the column we're ending on */
/* */
} /* */
if(l2x>=csv_rows || l3x>=csv_rows){ /* if we're beyond the edge of the table*/
l2_max_depth = l2x; /* store end position of l2 list */
return col_start+current_width-1; /* return the column we're ending on */
} /* */
} /* */
} /* */
After we pass through every column in our level 2 table, we can increment our level 2 row counter, and then check to see if the next level 1 data row is starting. We are assuming that the next level 1 data row is starting if the first column of level 1 data on the next row contains data (which is a pretty safe assumption, given that it’s a required field in this format anyway). If it does contain data, we report the maximum depth, store the maximum depth as a global variable for our level 1 function to use, and return the index of the last column in this table, so our level 1 function can resume from that point.
We also have a test after this to see if we’re beyond the edge of the table. If this has happened, it means that our level 2 table ends here, and we need to return our max depth and column widths. If we didn’t have this, we, again, might get stuck in an infinite loop, where our program keeps trying to load a next row that doesn’t exist.
/****************************************/
int process_l3_nested_list(string key,int col_start,int l3x_start){ /* */
... omitted variable declarations ...
l3x = 0; /* reset level 3 counter */
size = GetStringLength(key); /* get size of prefix string */
for(ix=0;ix<size;ix++){ /* scan string */
if(key[ix]==':'){ /* if this is a colon char */
end_prefix = ix; /* store last colon pos */
} /* */
} /* */
prefix = GetStringSegment(key,0,end_prefix); /* get prefix */
keystart = FindInList(keys,key); /* find first occurance of prefix */
size = ArrayGetAxisDepth(keys); /* get length of keys */
ix = keystart; /* set the start of the search */
for (ix; ix < size; ix++){ /* for each item in the array */
kix = FindInString(keys[ix],prefix); /* get the key index */
test_level = get_level(keys[ix]); /* run the level test */
if (kix >= 0 && test_level == 3){ /* if the next col has same prefix */
current_width++; /* increment width */
} /* */
else{ /* */
ix = size; /* end loop */
} /* */
} /* */
The process_l3_nested_list function functions almost identically to the level 2 version, just with many of the counters and variables replaced with level 3 versions instead of their level 2 counterparts. We start off the exact same way, by getting the prefix of our current key and finding the width of the level 3 table by checking each key to see where the prefix of our current table ends.
next_l3_row = -1; /* set the next level 3 row */
while(true){ /* loop until invalid data */
for (ix = 0; ix < current_width; ix++){ /* for each cell in width */
key = keys[keystart+ix]; /* get the key */
val = csv[l3x_start + l3x][col_start+ix+1]; /* value to set */
if(ix==0){ /* if this is the first cell */
if(val == ""){ /* if cell is empty */
return col_start + current_width; /* return the column we're ending on */
} /* */
else{ /* if the cell is not empty */
next_l3_row++; /* increment next L3 Row Counter */
} /* */
} /* */
Once we have the width, we can grab the key and value from our keys and csv arrays respectively, and if it’s the first row, we can return our width back to our level 2 processor if the value is empty. We can increment our level 3 row counter and move on if not.
new_key = FormatString(keys[keystart+ix],next_row, /* key to use */
next_l2_row,next_l3_row); /* key to use */
AddMessage(" Found Value: %s",val); /* display value */
val = TrimPadding(val); /* trim padding */
if(val!=""){ /* if we have a value to add */
if (MakeLowerCase(val) == "yes" || /* if data is Yes */
MakeLowerCase(val) == "no"){ /* or if data is No */
val = FormatString("%c",val[0]); /* truncate to first character */
} /* */
rc = EDACSetItem(edac,new_key, val); /* run EDAC update */
if(IsError(rc)){ /* if we have an EDAC error */
errors++; /* add error to log */
LogSetMessageType(LOG_ERROR); /* set log type to error */
AddMessage(" Cannot add %s value '%s', code %0x", /* log error */
new_key,val,rc); /* log error */
LogSetMessageType(LOG_NONE); /* set back to normal */
} /* */
else{ /* if not an EDAC error */
AddMessage(" Added %s value '%s'.", /* log success */
new_key,val); /* log error */
} /* */
} /* */
} /* */
This next segment of code is basically copy/pasted from the level 2 function, just with variable names changed. We can create the key with the FormatString function, and if the value is valid, once more us the EDACSetItem function to set it into our table. We then test the return code to see if it was accepted or not.
l3x++; /* increment row counter */
if(csv[l3x_start + l3x][level_2_data_start+1]!=""){ /* if the next data row is starting */
return col_start+current_width-1; /* return the column we're ending on */
/* */
} /* */
if(l3x>=csv_rows || l3x>=csv_rows){ /* if we're beyond the edge of the table*/
return col_start+current_width-1; /* return the column we're ending on */
} /* */
} /* */
} /* */
This section is a little simpler than the corresponding level 2 version. We can simply increment the level 3 row counter after we’ve iterated over all columns, and if we see another level 2 row starting, we return our width back to level 2 for processing. If we are beyond the edge of the table, we also return our width back to level 2 for processing. We don’t need to keep track of the depth of our level 3 table here since the bookkeeping for that is done as part of the level 2 process.
/****************************************/
int get_level(string element){ /* get the level of the element */
/****************************************/
int count; /* number of parts */
string parts[]; /* parts of a string */
/* */
parts = ExplodeString(element,"[%03d]"); /* explode string based on level dir */
count = ArrayGetAxisDepth(parts)-1; /* return number of parts */
return count; /* return number of parts */
} /* */
The final function here is get_level, which very simply explodes a given key and returns the number of string pieces in the result. This will correspond to the level of the key.
This is an example of the kind of flexible import you can run using EDAC with Legato. This obviously only handles a single portion of the file, but it can be expanded much further with further work. I think it provides a good look into some of the more advanced importers that can be written with the language.
Here’s the complete script for importing NPORT Part C into GoFiler:
#define FILENAME "C:\\Users\\steven.horowitz\\Desktop\\Part C.csv"
int process_table ();
int process_l2_nested_list (string key,int col_start,int l2x_start);
int process_l3_nested_list (string key,int col_start,int l3x_start);
int get_level (string element);
handle edac; /* handle to the edac */
string csv[][]; /* csv table from file */
int width; /* width of CSV sheet */
int csv_rows; /* rows in CSV sheet */
int level_1_data_start; /* the first column with data */
int next_row; /* number of next row to be added */
int next_l2_row; /* number of next l2 row to be added */
int next_l3_row; /* number of next l3 row to be added */
int level_2_data_start; /* the first level 2 column with data */
int l2_max_depth; /* max depth of an l2 list */
int l3_max_depth; /* max depth of an l3 list */
int l1x; /* Level 1 Depth */
int l2x; /* Level 2 Depth */
int l3x; /* Level 3 Depth */
int errors; /* number of import errors */
string keys[]; /* an array of key names */
/****************************************/
int main(){ /* main function */
/****************************************/
int rc; /* return code */
int ix; /* counter variable */
int cx; /* column counter */
string vals[]; /* values */
string directive; /* directive to enter */
string data; /* value to enter */
/* */
ArrayClear(csv); /* clear CSV */
csv = CSVReadTable(FILENAME); /* read the file */
rc = GetLastError(); /* get error code */
if (IsError(rc)){ /* if we have an error */
MessageBox('x',"Cannot read file %s",FILENAME); /* display error */
return ERROR_EXIT; /* return error */
} /* */
csv_rows = ArrayGetAxisDepth(csv); /* get depth of CSV */
width = ArrayGetAxisDepth(csv,1); /* get width of CSV */
AddMessage("Rows in data set: %d",csv_rows); /* display message */
rc = RunMenuFunction("FILE_NEW_SUBMISSION", "Form:NPORT-P"); /* create the NPORT filing */
if (IsError(rc)){ /* if it's an error */
AddMessage("Error: 1 %0xd",rc); /* return error */
return ERROR_EXIT; /* return */
} /* */
edac = EDACOpenView(); /* */
rc = process_table(); /* process list table */
return ERROR_NONE; /* return without error */
} /* */
/****************************************/
int process_table(){ /* process table directive */
/****************************************/
int positions[]; /* an array of position */
int levels[]; /* depth of columns */
int level; /* the depth of a specific column */
int position; /* int position */
int rc; /* return code */
int rx; /* row data counter */
int ix; /* counter */
int cx; /* counter */
int size; /* size of array */
int temp; /* temp variable */
int row; /* row to start processing on */
int next_col; /* next column to check */
string rowdata[][]; /* table row to add */
string oldval; /* previous vlaue */
string val; /* value */
string key; /* key for array */
string directive; /* directive of table */
boolean emptyval; /* true if a cell is empty */
/* */
AddMessage("Beginning processing table"); /* add message */
row = 0; /* start on row 0 */
ArrayClear(keys); /* reset keys list */
level_1_data_start = 1; /* store column of data start */
l1x = 0; /* level 1 index */
l2x = 0; /* level 2 index */
l3x = 0; /* level 3 index */
next_row = -1; /* init next row */
for(ix=1; ix<width; ix++){ /* for each column in CSV */
val = TrimString(csv[row][ix]); /* get value in cell */
if(val!=""){ /* if a value is there */
positions[cx] = ix; /* store position */
keys[cx] = val; /* store value */
levels[cx] = get_level(val); /* get the level of the key */
cx++; /* increment counter */
} /* */
} /* */
AddMessage("Columns - %d",cx); /* get number of columns */
while(true){ /* while next directive is not end list */
l1x++; /* increment row counter */
if(l1x>=csv_rows){ /* if we're beyond the edge of the table*/
return ERROR_NONE; /* return no error */
} /* */
next_row++; /* increment ID of next row */
for(ix=0; ix<cx; ix++){ /* for each column */
level = levels[ix]; /* get the level */
if(level > 1){ /* if we have a multi-level table */
if(level == 2){ /* if it's a level 2 list */
next_col = process_l2_nested_list(keys[ix], ix, /* */
row+l1x); /* pass level start point info */
} /* */
if(next_col <= ix){ /* should never happen */
return ERROR_EXIT; /* return with error */
} /* */
ix = next_col; /* set to next column to process */
} /* */
else{ /* if level 1 */
key = keys[ix]; /* get key */
position = positions[ix]; /* get position of value */
val = csv[row+l1x][position]; /* get value */
if(val!=""){ /* if value is defined */
AddMessage(" Found L1 field %s, value '%s'", key, val); /* log message */
} /* */
if(key!=""){ /* if this column has a key */
val = TrimPadding(val); /* trim padding */
if(val!=""){ /* if the field has a value */
if (MakeLowerCase(val) == "yes" || /* if data is Yes */
MakeLowerCase(val) == "no"){ /* or if data is No */
val = FormatString("%c",val[0]); /* truncate to first character */
} /* */
key = FormatString(key,next_row); /* format string for key */
rc = EDACSetItem(edac,key, val); /* run EDAC update */
if(IsError(rc)){ /* if we have an EDAC error */
errors++; /* add error to log */
LogSetMessageType(LOG_ERROR); /* set log type to error */
AddMessage(" Cannot add L1 %s value '%s', code %0x", /* log error */
key,val,rc); /* log error */
LogSetMessageType(LOG_NONE); /* set back to normal */
} /* */
else{ /* if not an EDAC error */
AddMessage(" Added %s value '%s'.", /* log success */
key,rowdata[ix][1]); /* log error */
} /* */
} /* */
} /* */
} /* */
} /* */
if(l2_max_depth > 1){ /* if l2 contains multiple rows */
AddMessage("L2 Depth is: %d",l2_max_depth); /* display message */
l1x += (l2_max_depth - 1); /* add the depth of L2 */
} /* */
l2_max_depth = 0; /* reset max depth of nested list */
} /* */
return ERROR_NONE; /* return no error */
} /* */
/****************************************/
int process_l2_nested_list(string key,int col_start,int l2x_start){ /* process nested list */
/****************************************/
int ix; /* counter */
int cx; /* column counter */
int size; /* size of table */
int current_size; /* size of current table */
int end_prefix; /* end of prefix string */
int keystart; /* the start index of the key */
int rc; /* return code */
int current_width; /* width of the current table */
int kix; /* key index */
int test_level; /* test level */
boolean has_value; /* true if row had a value */
string val; /* value to use */
string new_key; /* key to use in table */
string prefix; /* prefix for nested table */
int level; /* current level of list */
/* */
/* */
level_2_data_start = col_start; /* get column this starts on */
l2x = 0; /* reset level 2 depth, new l2 list */
size = GetStringLength(key); /* get size of prefix string */
for(ix=0;ix<size;ix++){ /* scan string */
if(key[ix]==':'){ /* if this is a colon char */
end_prefix = ix; /* store last colon pos */
} /* */
} /* */
prefix = GetStringSegment(key,0,end_prefix); /* get prefix */
keystart = FindInList(keys,key); /* find first occurance of prefix */
size = ArrayGetAxisDepth(keys); /* get length of keys */
for(ix=keystart;ix<size;ix++){ /* for each item in the array */
kix = FindInString(keys[ix],prefix); /* find key index */
if(kix>=0){ /* if the next col has same prefix */
current_width++; /* increment width */
} /* */
else{ /* */
ix=size; /* end loop */
} /* */
} /* */
AddMessage("Process L2 List, Width: %d",current_width); /* display message */
next_l2_row = -1; /* the next row in l2 to use */
while(true){ /* loop until invalid data */
for(ix = 0; ix < current_width; ix++){ /* for each cell in width */
key = keys[keystart+ix]; /* get the key */
if(get_level(key)==3){ /* if this is a level 3 key */
ix+=process_l3_nested_list(key,col_start+ix, /* process the level 3 list */
l2x_start+l2x); /* */
} /* */
else{ /* if it's level 2 */
val = csv[l2x_start + l2x][col_start+ix+1]; /* value to set */
if(ix==0){ /* if this is the first cell */
if(val == ""){ /* if cell is empty */
break; /* go for next row */
} /* */
else{ /* if the cell is not empty */
next_l2_row++; /* increment next L2 Row Counter */
} /* */
} /* */
new_key = FormatString(keys[keystart+ix],next_row, /* key to use */
next_l2_row); /* key to use */
AddMessage(" Found Value: %s",val); /* display value */
val = TrimPadding(val); /* trim padding */
if(val!=""){ /* if we have a value to add */
if (MakeLowerCase(val) == "yes" || /* if data is Yes */
MakeLowerCase(val) == "no"){ /* or if data is No */
val = FormatString("%c",val[0]); /* truncate to first character */
} /* */
rc = EDACSetItem(edac,new_key, val); /* run EDAC update */
if(IsError(rc)){ /* if we have an EDAC error */
errors++; /* add error to log */
LogSetMessageType(LOG_ERROR); /* set log type to error */
AddMessage(" Cannot add %s value '%s', code %0x", /* log error */
new_key,val,rc); /* log error */
LogSetMessageType(LOG_NONE); /* set back to normal */
} /* */
else{ /* if not an EDAC error */
AddMessage(" Added %s value '%s'.", /* log success */
new_key,val); /* log error */
} /* */
} /* */
}
} /* */
l2x++; /* increment row counter */
if(csv[l2x_start + l2x][level_1_data_start]!=""){ /* if the next data row is starting */
if(l2x>l2_max_depth){ /* if this is the deepest L2 yet */
AddMessage("Max L2 Depth: %d",l2x); /* Add Message */
l2_max_depth = l2x; /* store end position of l2 list */
} /* */
return col_start+current_width-1; /* return the column we're ending on */
/* */
} /* */
if(l2x>=csv_rows || l3x>=csv_rows){ /* if we're beyond the edge of the table*/
l2_max_depth = l2x; /* store end position of l2 list */
return col_start+current_width-1; /* return the column we're ending on */
} /* */
} /* */
} /* */
/****************************************/
int process_l3_nested_list(string key,int col_start,int l3x_start){ /* */
int ix; /* counter */
int cx; /* column counter */
int size; /* size of table */
int current_size; /* size of current table */
int end_prefix; /* end of prefix string */
int keystart; /* the start index of the key */
int rc; /* return code */
int current_width; /* width of the current table */
int kix; /* key index */
int test_level; /* test level */
boolean has_value; /* true if row had a value */
string val; /* value to use */
string new_key; /* key to use in table */
string prefix; /* prefix for nested table */
int level; /* current level of list */
/* */
l3x = 0; /* reset level 3 counter */
size = GetStringLength(key); /* get size of prefix string */
for(ix=0;ix<size;ix++){ /* scan string */
if(key[ix]==':'){ /* if this is a colon char */
end_prefix = ix; /* store last colon pos */
} /* */
} /* */
prefix = GetStringSegment(key,0,end_prefix); /* get prefix */
keystart = FindInList(keys,key); /* find first occurance of prefix */
size = ArrayGetAxisDepth(keys); /* get length of keys */
ix = keystart; /* set the start of the search */
for (ix; ix < size; ix++){ /* for each item in the array */
kix = FindInString(keys[ix],prefix); /* get the key index */
test_level = get_level(keys[ix]); /* run the level test */
if (kix >= 0 && test_level == 3){ /* if the next col has same prefix */
current_width++; /* increment width */
} /* */
else{ /* */
ix = size; /* end loop */
} /* */
} /* */
next_l3_row = -1; /* set the next level 3 row */
while(true){ /* loop until invalid data */
for (ix = 0; ix < current_width; ix++){ /* for each cell in width */
key = keys[keystart+ix]; /* get the key */
val = csv[l3x_start + l3x][col_start+ix+1]; /* value to set */
if(ix==0){ /* if this is the first cell */
if(val == ""){ /* if cell is empty */
return col_start + current_width; /* return the column we're ending on */
} /* */
else{ /* if the cell is not empty */
next_l3_row++; /* increment next L3 Row Counter */
} /* */
} /* */
new_key = FormatString(keys[keystart+ix],next_row, /* key to use */
next_l2_row,next_l3_row); /* key to use */
AddMessage(" Found Value: %s",val); /* display value */
val = TrimPadding(val); /* trim padding */
if(val!=""){ /* if we have a value to add */
if (MakeLowerCase(val) == "yes" || /* if data is Yes */
MakeLowerCase(val) == "no"){ /* or if data is No */
val = FormatString("%c",val[0]); /* truncate to first character */
} /* */
rc = EDACSetItem(edac,new_key, val); /* run EDAC update */
if(IsError(rc)){ /* if we have an EDAC error */
errors++; /* add error to log */
LogSetMessageType(LOG_ERROR); /* set log type to error */
AddMessage(" Cannot add %s value '%s', code %0x", /* log error */
new_key,val,rc); /* log error */
LogSetMessageType(LOG_NONE); /* set back to normal */
} /* */
else{ /* if not an EDAC error */
AddMessage(" Added %s value '%s'.", /* log success */
new_key,val); /* log error */
} /* */
} /* */
} /* */
l3x++; /* increment row counter */
if(csv[l3x_start + l3x][level_2_data_start+1]!=""){ /* if the next data row is starting */
return col_start+current_width-1; /* return the column we're ending on */
/* */
} /* */
if(l3x>=csv_rows || l3x>=csv_rows){ /* if we're beyond the edge of the table*/
return col_start+current_width-1; /* return the column we're ending on */
} /* */
} /* */
} /* */
/****************************************/
int get_level(string element){ /* get the level of the element */
/****************************************/
int count; /* number of parts */
string parts[]; /* parts of a string */
/* */
parts = ExplodeString(element,"[%03d]"); /* explode string based on level dir */
count = ArrayGetAxisDepth(parts)-1; /* return number of parts */
return count; /* return number of parts */
} /* */
 Steven Horowitz has been working for Novaworks for over five years as a technical expert with a focus on EDGAR HTML and XBRL. Since the creation of the Legato language in 2015, Steven has been developing scripts to improve the GoFiler user experience. He is currently working toward a Bachelor of Sciences in Software Engineering at RIT and MCC. Steven Horowitz has been working for Novaworks for over five years as a technical expert with a focus on EDGAR HTML and XBRL. Since the creation of the Legato language in 2015, Steven has been developing scripts to improve the GoFiler user experience. He is currently working toward a Bachelor of Sciences in Software Engineering at RIT and MCC. |
Additional Resources
Legato Script Developers LinkedIn Group
Primer: An Introduction to Legato


