Working with text inside of tables when looking at HTML code can sometimes be a daunting task. Looking at rows of code that are rows and columns can be difficult, especially when trying to write a script to read text from within a table. Keeping track of what row and cell you are in sometimes can feel like an entire script in itself. Luckily for us we have a number of functions in Legato that can allow us to read data from a table as though we were looking at a spreadsheet. This means that we can focus on developing tools to focus on aggregating the data itself rather than reinventing the wheel every time that we want to retrieve data from a table.
Friday, July 12. 2019
LDC #143: Table Mapping Tools
The first thing to do before we can use any of the HTML Table functions is we need to map the table to an HTML Table Map Object. This is done by using the HTMLTableMap() function. The function definition looks like this:
handle = HTMLTableMap ( string data | handle hObject, [int pos] | [int x, int y] );
We can give the function either a string of data or a handle to an SGML, Mapped Text, or Edit Object. This is the text that will be mapped into our object. If the table does not start at the beginning of the string or object we can pass the starting position as either a single int for a string or an x and y position for an SGML, Mapped Text, or Edit Object. The function returns a handle to an HTML Table Map Object or NULL_HANDLE if an error occurs during the mapping. It is always a good idea to check to see if the handle is null before continuing onward in a script.
Now that we have an HTML Table Map Object we can perform a number of different operations on it in order to retrieve data:
Columns: HTMLTableGetColumnCount — Returns the number of columns in a table. HTMLTableGetColumnProperties — Returns properties for a column at a column position or discrete index. HTMLTableGetDiscreteCount — Returns the number of discrete columns in the table. HTMLTableGetWidths — Returns column widths in the form of a string array. HTMLTableGetWidthValues — Returns column widths in the form of a pvalue array. Rows: HTMLTableGetRowCount — Returns the number of rows in a table. Cells: HTMLTableGetCell — Gets the raw content (HTML) of a table cell. HTMLTableGetCellAsText — Gets the content of a table cell as text. HTMLTableGetCellProperties — Gets the properties for a specified cell.
These functions have been split up based upon what part of the table the function works with: column, row, or cell. I’m going to quickly talk about each of these functions so that you can be a pro in reading HTML tables in no time.
Let’s start by talking about the singular row function: HTMLTableGetRowCount(). This function is a simple function that returns the number of rows in the table as an integer. If we were going to start iterating through rows to find values in a balance sheet, for example, we can use this function to find the end of our loop.
Next let’s go through some of the column functions, starting with HTMLTableGetColumnCount(). This is the equivalent of the row function. Sometimes, however, you cannot tell which column is which just by looking at the table because some of the cells are spanned across multiple columns. In this case we have an additional function HTMLTableGetDiscreteCount() which returns the number of discrete columns in a table. Discrete columns are column definitions that are unique. For example, if the first cell in the first row has no span on it, this is considered a discrete column. If the first column in the second row has a colspan of two, this is also a discrete column as it is a uniquely sized column. To see an example of this, let’s look at this table:

Each of the cells that are highlighted in blue are discrete columns. So while HTMLTableGetColumnCount() would return five, HTMLTableGetDiscreteCount() would return eight, each of which are counted out by the numbers in red.
The next two functions we are going to talk about are HTMLTableGetWidths() and HTMLTableGetWidthValues(). These are similar in the fact that they will both return the widths of each column in an array. The only difference is that HTMLTableGetWidths() will return a string array, while HTMLTableGetWidthValues() will return a dword array. One thing to keep in mind with these functions is that there is a chance that a poorly coded HTML table will return a different number of widths than the number of columns returned by HTMLTableGetColumnCount(). For example, if you have a table where all of the cells in the first column have a colspan of at least two you will get one less width in the widths array than number of columns reported by HTMLTableGetColumnCount(). It is my suggestion if you are going to be iterating over column widths to use the ArrayGetAxisDepth() function to determine how many widths you have as opposed to relying on the HTMLTableGetColumnCount() function.
It is one thing to find out the size and shape of our table, but another important part is reading the text out of a table cell. Our next two functions do just that. First we have the HTMLTableGetCell() function. We pass three variables to it: the Table Map Object handle, an integer of the row we want to retrieve, and an integer of the column we want to retrieve. The function returns a string which contains the raw HTML of the cell. This string will be empty if the cell is empty or if the function encounters an error. Our other option for retrieving values of cells is HTMLTableGetCellAsText(). This function is called using the same variables as the HTMLTableGetCell() function, but instead of a string of HTML being returned, HTMLTableGetCellAsText() returns the translated contents of a cell. HTMLTableGetCellAsText() will only return characters that have been converted to ANSI. UNICODE characters that cannot be translated are returned as ‘?’ in the string. One important thing to note with both HTMLTableGetCell() and HTMLTableGetCellAsText() is that if the cell your are referencing is not an addressable cell, i.e. it has been spanned over, the return string will be empty.
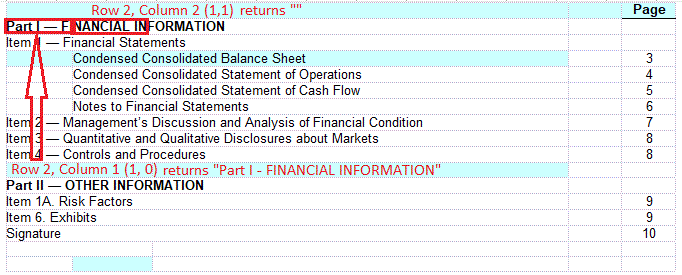
If we look at our example table again and we pass ‘1’ as the row and ‘1’ as the column to the function (asking for the content of the second column of the second row) we will get an empty string returned as the content for that cell can only be retrieved by asking for the first column of that row.
We’re almost done now. The last two functions we need to talk about are the functions that we are going to use to get properties from columns or cells. These properties include attributes such as background-color, class, and width. The function definitions are as follows:
string [] = HTMLTableGetColumnProperties ( handle hTable, int pos, [int span] ); string [] = HTMLTableGetCellProperties ( handle hTable, int row, int column );
As you can see both of these functions require the HTML Table Map Object handle and then the position of the cell in question. The HTMLTableGetColumnProperties() function can have the following possible array keys:
DiscreteIndex ColumnPosition ColumnSpan background-color class text-align vertical-align width ContentFlags
The DiscreteIndex, ColumnPosition, and ColumnSpan variables all have to do with the positioning of the cell, while the rest of the keys other than ContentFlags are based off the CSS attributes for the column. Finally, the ContentFlags index is a bitwise value that includes hints about column content such as if the column is a gutter column, if the column has data in it, and what kind of data (textual or financial) is in the column. For a complete explanation of all of the flags, see the Legato help documentation.
The HTMLTableGetCellProperties() function has more HTML attributes, CSS properties, and control flags that you can use:
ABBR - Abbreviation or abbreviated form. Deprecated, not presented in properties if not present in tag. AXIS - Category for cells. Deprecated, not presented in properties if not present in tag. CLASS - CSS class name for cell. Not presented in properties if not present in tag. COLSPAN - Number of columns to span. Not presented in properties if not present in tag. HEADERS - Related header. Not presented in properties if not present in tag. ID - Unique namespace ID for element. Not presented in properties if not present in tag. ROWSPAN - Number of rows to span. Not presented in properties if not present in tag. SCOPE - Scope of cell. Deprecated, not presented in properties if not present in tag. TITLE - Title for tag. Not presented in properties if not present in tag. BackgroundColor - Background color in CSS form. If specified as HTML attribute, it is translated to CSS. Not presented in properties if not present in tag. Height - Specified height of the cell. If specified in HTML, it is translated to CSS. Not presented in properties if not present in tag. TextAlign - Horizontal content align in CSS form. If specified as HTML attribute, it is translated to CSS. Not presented in properties if not present in tag. VerticalAlign - Vertical content align in CSS form. If specified as HTML attribute, it is translated to CSS. Not presented in properties if not present in tag. Width - Specified width of the cell. If specified in HTML, it is translated to CSS. Not presented in properties if not present in tag. Position - Zero-based column position. DiscretePosition - The Discrete Column Position in the column array. Note that the order of the columns is not necessarily linear. ColumnSpan - Calculated column span, ‘1’ if no span. RowSpan - Calculated row span, ‘1’ if no span. c_y c_x - Two parameters specifying the row and column position with the table matrix. d_sx d_sy d_ex d_ey - The zero-based X/Y position within the source file/object excluding the open and close tags. This specifies the content area. t_sx t_sy t_ex t_ey - The zero-based X/Y position within the source file/object including the open and close tags. ControlFlags - A hex representation of bitwise control flags, See Legato Documentation. ContentFlags - A hex representation of bitwise content flags, See Legato Documentation. StyleFlags - A hex representation of bitwise style flags, See Legato Documentation. Element - HTML element name for cell. ElementToken - A hex representation of the DTD token value for the item.
Together, these functions represent a large amount of power given to us to parse through tables in an HTML document. Being able to read tables like a datasheet allows us to easily parse through tables to find the data that we are looking for. This means that building a script to aggregate data becomes a snap rather than a chore.
 Joshua Kwiatkowski is a developer at Novaworks, primarily working on Novaworks’ cloud-based solution, GoFiler Online. He is a graduate of the Rochester Institute of Technology with a Bachelor of Science degree in Game Design and Development. He has been with the company since 2013. Joshua Kwiatkowski is a developer at Novaworks, primarily working on Novaworks’ cloud-based solution, GoFiler Online. He is a graduate of the Rochester Institute of Technology with a Bachelor of Science degree in Game Design and Development. He has been with the company since 2013. |
Additional Resources


